| 慢sql查询,慢sql优化,常用的Oracle函数 | 您所在的位置:网站首页 › oracle中not in速度慢 › 慢sql查询,慢sql优化,常用的Oracle函数 |
慢sql查询,慢sql优化,常用的Oracle函数
|
一.慢sql优化
1.数据库设计
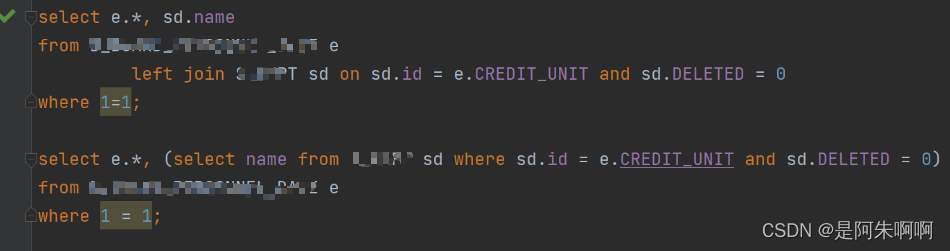
①数据量多可考虑分表分库(垂直分割,水平分割) ②索引:看看有没有索引,没有就加索引,有的话就通过explain看看有没有命中索引,索引有没有失效,索引并不是越多越好,多的话会导致结构变的复杂,修改会变慢 2.代码层面①循环里面尽量不要多次执行sql,多次连接和关闭都需要时间,使用批量执行可以节省连接和关闭的时间 ②先查询条数,如果条数不为零才继续执行查询sql 3.sql层面①in里面不要右太多的元素,如果有那就分组,用left join替换in最好 ②可以使用not exists先查询条数,看看有没有 ③可以使用分页,但是深度分页会导致很慢 ④避免排序,不仅仅是order by会排序group by,聚合函数,distinct也会排序 ⑤查一个字段,在from后面用left join on然后在上面在表.字段 要比在上面直接select 这个字段要快 如图所示,第一种就比较快
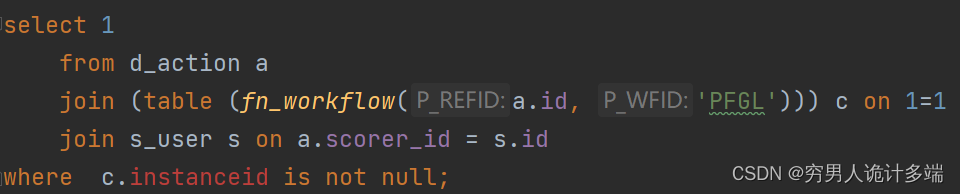
⑥使用join on 先对数据进行减少,再使用函数对数据进行处理就很快了 sql如下,原sql很长这里精简了下,表d_action这里称表a,下同,表a是一个一万多条的记录表,表c是通过函数fn_workflow中传入表a的id得到的一张主要用到的表,表s是用来查询用户信息的关联表
这里主要是通过函数查询主要表中的数据,有instanceid则是需要的数据,这条sql需要执行高达15秒,
换成这样快一点点,但依旧很慢 ,原因则是因为通过join 和left join得到的聚合表仍旧有一万多条,这时有一万多条数据都要使用函数fn_workflow这是很慢的
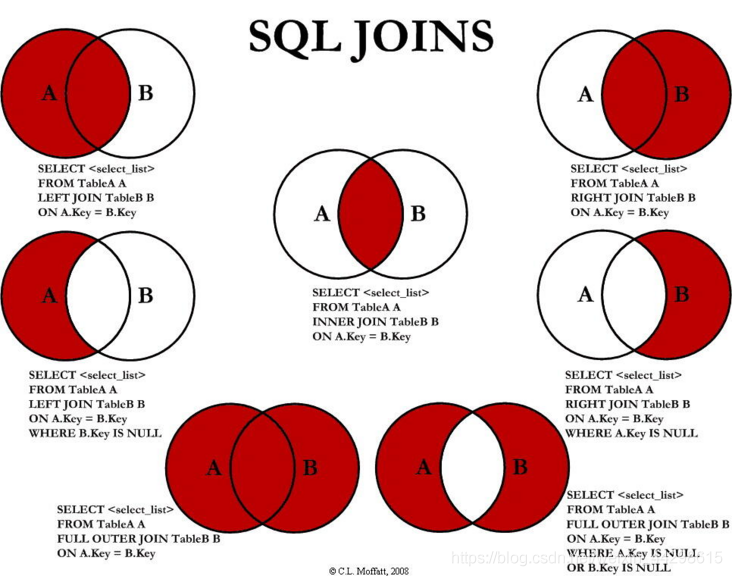
此时把s_user中left join on 换成join on就显著提升了,因为内连接先会把表a中的一些没用的数据筛选一部分从一万多条变成了一百多条,这时一百多条再使用fn_workflow这个函数就很快了; 二、sql的知识点 1.左连接,右连接等
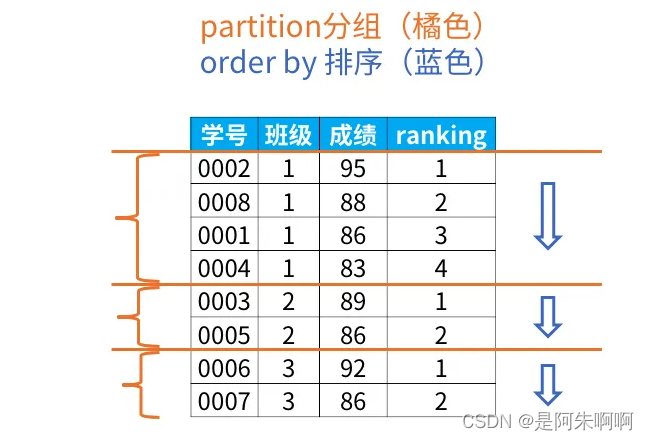
执行顺序: 1. 内连接:先取出符合连接条件的行,再根据where条件筛选出符合条件的行,形成最终结果集。 2. 左连接:以左表为基础,取出符合连接条件的行,再将右表中符合条件的行加入结果集中,最后根据where条件筛选出符合条件的行。 3. 右连接:以右表为基础,取出符合连接条件的行,再将左表中符合条件的行加入结果集中,最后根据where条件筛选出符合条件的行。 4. 全连接:取出左表和右表中所有符合连接条件的行,将其组合成结果集,若某一表中没有符合条件的行,则相应列的值为null。最后根据where条件筛选出符合条件的行。 2.Case When Then 用法 语法:case when 条件1 then 返回值1 when 条件2 then 返回值2 else 默认返回值 end 列名 举例:有一张表,里面有3个字段:语文,数学,英语。其中有3条记录分别表示语文70分,数学80分,英语58分, 请用一条sql语句查询出这三条记录并按以下条件显示出来(并写出您的思路): 大于或等于80表示优秀,大于或等于60表示及格,小于60分表示不及格。 显示格式: 语文 数学 英语 及格 优秀 不及格 SQL: select case when yw=60 and yw=70 and yw80 then '优良' end as '语文', case when sx=60 and sx =70 and sx80 then '优良' end as '数学' from St3.窗口函数over 用法 语法 over (partition by order by ) 注意:1.窗口函数可以放专用窗口函数,比如rank, dense_rank, row_number等, 2.也可以放聚合函数,如sum. avg, count, max, min等 功能:1.同时具有分组(partition by)和排序(order by)的功能 2.不减少原表的行数,所以经常用来在每组内排名 注意事项:窗口函数原则上只能写在select子句中 举例:select *,rank() over (partition by 班级order by 成绩 desc) as rankingfrom 班级表
 https://www.zhihu.com/tardis/bd/art/92654574?source_id=1001
4.merge into
语法: https://www.zhihu.com/tardis/bd/art/92654574?source_id=1001
4.merge into
语法:
merge into 表A using 表B on 条件 when not matched then 添加或修改语句 解析:当满足条件时用表b的数据更新表a,当不满足条件时执行语句 详细学习的链接merge into 的用法_一个懒鬼的博客-CSDN博客 dual简单来说是一个空表,是oracle提供的最小的工作表,只有一行一列,具有某些特殊功用,所有用户都可以使用dual名称访问。 例如:执行一个查看当前日期的语句 select sysdate from dual; 放在任何一个oracle数据库当中都不会报错,所以一般做一些特定查询的时候用这个表是最稳妥的 查看当前用户 select user from dual; select count(*) from dual; 用作计算器 select 70*9*10-16 from dual; 调用系统函数 (1) 获得当前系统时间 select sysdate from dual; select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual; (2)获得随机数 select DBMS_RANDOM.random from dual; (3)获得主机名 select sys_context('userenv','terminal') from dual; (4)获得当前locale select sys_context('userenv','language') from dual; 6.withOracle 中可用with来构建一个临时表,但MySQL不支持with,对应临时表,MySQL可通过小括号的方式来处理,但构建的临时表必须设置临时表名。 -- Oracle with使用 WITH TMPTAB AS (SELECT A.DEPID FROM FW_DEPARTMENT A) SELECT DEPID FROM TMPTAB-- MySQL 构建临时表使用(此处必须给括号中的临时表设置表名) select b.depidfrom (select depidfrom fw_department) b 7.nvlNVL()函数是Oracle中的一个函数,NVL()函数的功能是实现空值的转换。 例如NVL(string1,replace_with)中: 当第一个参数(string1)为空时,返回第二个参数(replace_with); 当第一个参数(string1)不为空时,则返回第一个参数(string1)。 NVL()函数的第一个参数和第二个参数类型必须相同,或者可以由隐式转换得到。 拓展:NVL2()函数:Oracle/PLSQL中的一个函数,Oracle在NVL函数的功能上扩展,提供了NVL2函数。 如NVL2(E1,E2,E3)中: 当E1为NULL时,返回E3;当E1不为NULL时,返回E2。 8.LISTAGG() WITHIN GROUP ()列转行 用法LISTAGG(列名,拼接的字符) WITHIN GROUP( ORDER BY '列名') 举例 select listagg(a.id,',,') within group ( order by PHONE) from S_USER a where NAME like '朱%';
|



【本文地址】